GenAI coding tools are genuinely powerful. In the right hands, in the right environment, the stuff is remarkable.
Experienced engineers with good practices around them are doing things in hours that used to take weeks. Ideas get tested that previously stayed as hypotheses. Long-standing technical debt is getting cleared. Work that wasn’t worth the investment a year ago is now done in an afternoon.
Right environment means organisations that genuinely understand software engineering. An appreciation that building software is not a production line, but a learning process.
Right hands means experienced software engineers who take full end to end ownership. Product mindset. XP practices. Continuous delivery with all the automation, tests and guardrails that let you learn and iterate quickly without breaking things.
Most organisations don’t have that, which is why most of the industry isn’t getting much from these tools.
The organisations best placed to benefit from GenAI are the ones who invested in engineering foundations years ago. For everyone else, the shortcut you were hoping for doesn’t exist.
For CEOs and founders hoping to benefit, the answer isn’t as simple as handing out Claude licences (as Jason Gorman puts it, “just because you attach a code-generating firehose to your plumbing, that doesn’t mean you’ll get a power shower”). It’s investing in the engineering culture and practices. Unglamorous, slow work, but there’s no way around it.
Footnote: By experienced I don’t mean “senior” by the way. Most “senior” engineers I meet have never worked in a genuine XP or continuous delivery environment. They have years of experience, just not the experience that matters.
Experienced in this context means having built and shipped software in organisations that understand the craft. Fast feedback, small batches, tests as a design tool, code as a liability to be managed. That’s not about title or tenure. It’s about the environment you learned in.
I’ve worked with many “juniors” with e.g. 2-4 years experience who run rings around people with 10+. Because they learned in the right environment from the start.
Anthropic’s Claude Code pricing fiasco is what it looks like when a company is squeezed at three ends. Anthropic quietly removed Claude Code from the $20 Pro plan, making it exclusive to the $100 and $200 Max tiers. Their Head of Growth framed it as a small test on 2% of new signups (which didn’t match what users were seeing). Within hours they reversed it.
What interests me is what the test reveals about the bind Anthropic is in. It was an attempt to fix unit economics: heavy users on flat-fee plans consume vastly more than the plans recover, and the Head of Growth, Amol Avasare, said as much on X – plans weren’t built for current usage patterns.
That’s one real pressure. But it’s not the only one. They’re squeezed three ways at once.
The first squeeze is unit economics. Someone running Claude Code all day on a $20 subscription costs far more to serve than they pay. Either prices go up or costs come down. However raising prices risks making them uncompetitive against OpenAI and Google, who are already taking advantage of this moment.
The second squeeze is compute. Claude has been below 99% uptime for a quarter. They are clearly struggling with the huge increase in demand they’re experiencing. A year ago the product was mostly chat. Today a significant share of usage is coding agents running for hours. Demand shape changing faster than provisioning can keep up.
So why not do what Gmail and Bluesky did and gate new signups? Match supply to demand, protect the experience for existing users, generate some FOMO and desirability in the process, and buy time to sort the rest out.
That brings us to the third squeeze. Anthropic’s valuation, like that of every frontier AI lab, rests on growth trajectory rather than current profitability. However dressed up, limiting signups reads as a capacity wall, and from there it’s a short step to growth slowing and the IPO narrative wobbling.
The best approach for managing the compute squeeze is ruled out by the growth squeeze, which means infrastructure strain has to be absorbed through rate limits and outages instead, upsetting all your existing users in the process.
It also means heavy users keep arriving, which continues to make the unit economics worse, which is how you end up running silent pricing tests on Tuesday afternoons.
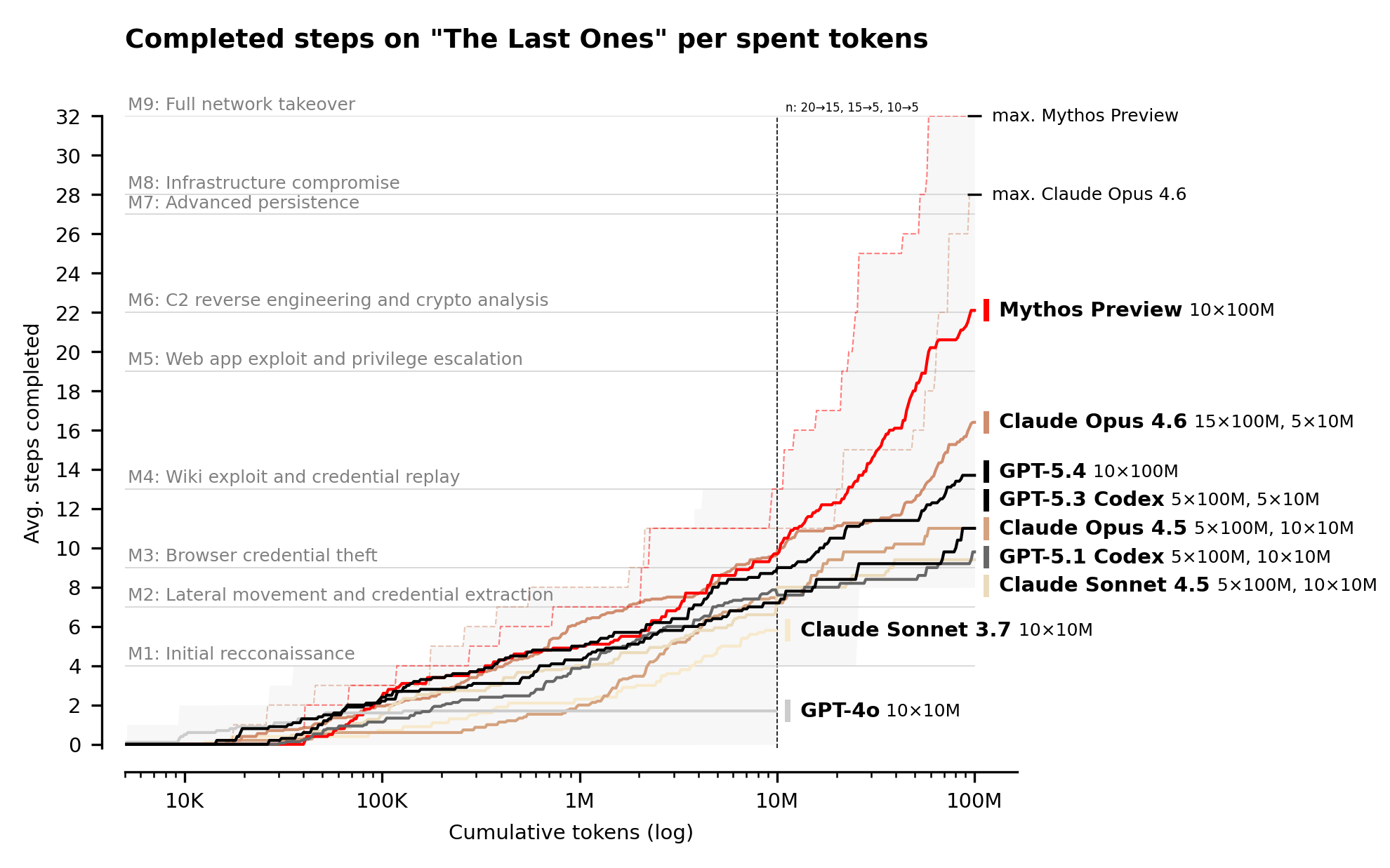
The UK’s AI Security Institute has published the first independent evaluation of Claude Mythos’s cyber capabilities. The headline finding – first AI model to complete a full 32-step simulated network attack – is notable. But there’s a finding buried in the accompanying methodology paper that puts it in a rather different light. On current pricing and reliability, according to my maths, a human expert would do the same job cheaper, faster and more reliably.
What AISI found
On capture-the-flag tasks – common security challenges AISI have been using to test models since 2023 – Mythos sits broadly on the existing trend line. Real improvement, but incremental, and not unique to Mythos. The capability has been building across multiple labs for over a year.
The more significant result is with what AISI call “chained attacks” – where a model has to execute a long sequence of steps across a network to take it over, rather than exploit a single vulnerability in isolation. AISI measured this using their “The Last Ones” simulation: a 32-step corporate network attack spanning initial reconnaissance through to full network takeover, which they estimate a human expert would complete in 14 hours.
Mythos is the first model to complete all 32 steps end to end – though Opus 4.6, Anthropic’s previous model, wasn’t far behind in its best run.
The limitations & takeaways
The model was already inside the network, and the simulated environment had no active security monitoring and no defensive tools. Real networks aren’t like that – at least they shouldn’t be.
For most organisations the biggest threats remain phishing, weak passwords, and unpatched systems. AISI’s own advice in the article reflects this: focus on the basics – patch regularly, enforce access controls, enable logging. More importantly, the most common and successful attacks continue to target humans rather than rely on technical sophistication – as the Co-op, M&S and JLR attacks last year demonstrated.
The trajectory is real and worth taking seriously – but AISI’s findings are more measured than Anthropic’s “watershed moment” framing, and the most important things you can do about it are the same things you should have been doing anyway.
There’s a finding buried in the methodology
AISI published an accompanying academic paper detailing the evaluation methodology and results for models prior to Mythos – including detailed cost and timing data. This is where things get interesting.
According to that paper, the best Opus 4.6 run at 100M tokens cost approximately $80 and took around 10 hours – completing 22 of 32 steps, equivalent to roughly 6 of those 14 human hours. Slower, and less than halfway through in human time equivalent.
Mythos is priced at 5x Opus 4.6 per token. Its best run completed 32 steps versus Opus 4.6’s 22 – but crucially the additional steps fall in the later, harder milestones which are significantly more time and token-intensive. Accounting for both the price differential and likely higher token usage on those harder steps, a rough extrapolation puts a Mythos run at approximately $880.
The variance problem
The paper shows all models have very high variance across runs. Opus 4.6’s best run reached 22 steps, its worst only 11, with an average of 15.6. And the AISI article shows Mythos only completed all 32 steps in 3 of its 10 attempts – a 70% failure rate on full completion.
To expect one successful outcome you’d need 3-4 runs on average – and each run is likely comparable in time to the Opus 4.6 runs.
That’s approximately $2,900-3,500 per successful outcome.
A human expert completing the same range: 14 hours, once, reliably. At $125-190 per hour (UK rates) that’s $1,750-2,625.
So at least today, and according to AISI data, and assuming my maths are roughly correct, an experienced cyber human would be cheaper, more reliable and at least as quick as the most capable AI model currently available.
You may be seeing posts claiming METR’s widely-cited 2025 study has been followed up with new research showing an 18% productivity boost. That’s not what the article says.
In 2025, METR found experienced open-source developers using GenAI were 19% slower – and notably, developers themselves thought they were being sped up. They started a new experiment to track how things were changing – but couldn’t complete it. They say the data was too compromised to produce reliable results.
The interesting part is why the study broke down. Developers are now so reliant on AI that they won’t work without it (to be part of the control group). And the nature of how they work when using GenAI has changed too, which undermines e.g. simple time-on-task measurements.
METR believe GenAI coding productivity is improving – but say they can no longer measure it reliably with this study design and are reworking their approach. Personally I don’t see how you can practically design an effective controlled experiment considering everyone uses it now.
Worth noting too that, either way, these kinds of studies are still a narrow window on software delivery – individual task completion by autonomous open-source contributors, not developers working in teams on production codebases with all the organisational complexity that entails.
Multiple studies now suggest AI is genuinely increasing coding velocity – including CircleCI’s recent State of Software Delivery report. But the same report points to a more troubling pattern at the system level: less code reaching production and increasing instability.
My take: teams with strong engineering practices – genuine continuous delivery, high code quality, solid test coverage – appear to be realising real benefits from GenAI, and there’s data to support that. The problem is those teams represent a small fraction of the industry. For everyone else, higher coding velocity is likely resulting in a negative impact downstream.
CircleCI’s 2026 State of Software Delivery report has two findings that are already travelling: AI is meaningfully boosting software delivery, but only 1 in 20 teams are capturing that benefit. Both claims are more uncertain than the report suggests, for different reasons.
What the report is measuring
The report’s primary metric is “throughput” – the number of times a CI pipeline runs per day. A CI pipeline is the automated process teams use to build, test and progress code toward production. It is not production deployments, it is not features shipped. The report is using pipeline execution data to infer things about software delivery. That’s not unreasonable – it’s real data – but it’s worth understanding what’s actually being measured before drawing conclusions.
The headline numbers
The report measures throughput on both feature branches and main branches and aggregates both into its headline figures. Throughput as a metric on feature branches is effectively meaningless. Throughput should be an end-to-end metric – feature branches aren’t end-to-end, they get merged to main. The only meaningful “throughput” measure is against the main branch. What the feature branch data actually shows is a lot more code being written, but not much more reaching production.
Average teams are up 4% on the aggregated figure, but main branch throughput is down 7%
The top 10% of teams show aggregated throughput up nearly 50%, main branch essentially flat
For 95% of teams, AI is generating more work in progress that isn’t shipping
The success rate of main branch builds compounds this further. It has fallen to 70.8%, its lowest in over five years – 30% of attempts to merge code for production are now failing.
The 1 in 20 claim
The report identifies the top 5% of teams as the only group seeing meaningful main branch throughput growth – 26% – and uses this to argue that some teams have cracked the AI delivery problem.
But the summary data for that group is odd. Their average CI pipeline duration is 6 seconds. A pipeline doing anything meaningful – compiling, running tests, scanning – it’s hard to think of a single CI step that legitimately completes in 6 seconds. Perhaps it is an error in the report. There’s also data that may be skewing the findings more broadly – one team apparently running 130,000 CircleCI workflows a day would have an outsized effect on any aggregate figures.
What to take from it
The integration bottleneck finding is credible. If you’re generating code faster than your team can review and integrate it (safely), that’s a genuine problem this data is consistent with.
The “1 in 20 teams have cracked it” conclusion is less solid than it appears. Not to say that some aren’t getting benefit I believe there are, however the data here for the teams making that case doesn’t add up clearly enough to draw confident lessons from.
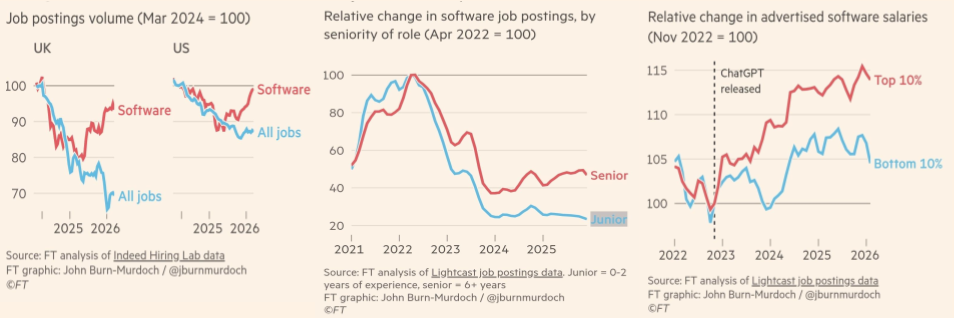
According to the FT, demand for software engineers is rising again, and in relative terms is outperforming the wider jobs market. That’s the headline most people will take away.
But the more important detail is that the growth is concentrated in more experienced roles, while entry-level hiring remains weak.
Genuinely strong, experienced engineers are already a relatively small pool. If the FT data is right, demand is increasingly being concentrated into that already constrained part of the market.
That means a supply squeeze. Salary inflation, harder hiring, slower execution, and more organisations unable to deliver on the strategy and goals they have set.
Further, as we saw in the pandemic hiring boom, shortage pressure creates title inflation and level distortion, such as mid-level people taking senior or lead roles at new companies. The result is organisations paying more for talent that is, on average, less experienced than the role implies, while carrying more execution risk and less capability depth than the org chart suggests.
If companies keep optimising away that layer, it is not just bad for the industry overall, it is economically short-sighted for the individual organisation. It increases future dependence on an already constrained and expensive part of the market, while missing the real value of junior engineers, not just what they contribute now, but the capability they become.
Parkinson’s Law is mainly interpreted as “people fill the time available”. That line was really only a hook. The original paper is really about how organisations create extra work and headcount for themselves, regardless of whether there is more genuinely useful work to do.
As organisations grow, work often grows around the work itself – layers, handoffs, approvals, reporting, internal dependency. More work about work.
That’s why adding more people, more process, more tooling (more AI?) so often fails to produce the productivity gains people expect.
Adding people can be beneficial to a point, but often far less than people might expect – and beyond a point, things usually get slower and more expensive, not faster. Doug Putnam’s analysis of hundreds of software projects found small teams were generally best, with 3-5 often the economic sweet spot, and larger teams quickly suffering diseconomies of scale.
The countermeasures to keep things as small, clear and contained as possible:
clear direction and priorities
clear accountability, ownership and decision boundaries
ruthless prioritisation
less work in flight – a culture of finishing
This is why I keep coming back to the same principle:
Fewer, better people doing less, better will usually get more done.
Not because small is always magically better. But because complexity compounds, and every extra person, process, dependency and priority adds drag.
Footnote: Probably the grossest misinterpretation of Parkinson’s Law is the idea that giving individuals less time or tighter deadlines will somehow make work happen faster. In practice, that will often just compresses time without removing the underlying drag.
All the available evidence suggests that GenAI-assisted coding is most powerful in the hands of highly experienced software engineers, while having neutral or even negative effects for less experienced ones.
It’s easy to see how this may be interpreted inside organisations. If experienced engineers can be made significantly more productive with GenAI, then it can appear rational to rely more heavily on that group. Smaller teams of senior engineers, supported by GenAI, with fewer junior or entry-level roles, can look like an attractive opportunity.
However, genuinely good, experienced software engineers are already scarce across the industry. It is difficult to put a precise figure on this, but studies on the impact of AI in software engineering suggest that only a minority of engineers and teams currently have the skills and experience needed to realise sustained benefits from GenAI-assisted software development, likely somewhere in the region of 10–30%.
That raises an obvious question about where the next generation of experienced engineers will come from.
The risk is not only that organisations hire fewer junior engineers, but that even when they do, the conditions for learning are compromised. A recent study by Anthropic, one of the organisations at the frontier of GenAI and the creators of the Claude models and tools such as Claude Code, found that developers using AI assistance completed coding tasks slightly faster but demonstrated significantly weaker understanding afterwards. When the tool was allowed to do too much of the thinking, learning suffered.
More generally, as organisations offload more work to these tools, team dynamics begin to shift. Fewer questions are asked. Explanation gives way to acceptance. Output rises, but shared understanding does not.
This all happens quietly. Everything looks efficient, right up until it’s not.
Despite repeated waves of tooling, the core skills that define good software engineering have remained remarkably stable. Effective problem-solving, system-level thinking, feedback, shared understanding, automated testing and iterative change have been recognised as good practice for decades.
Learning is not just an individual concern. Software development is a learning activity at every level. Teams learn about users, systems, risks, and constraints through the work itself.
What has also remained true, despite this being well understood, is that only a minority of the industry consistently applies them. The evidence also increasingly suggests these practices are becoming even more relevant in the age of GenAI.
GenAI accelerates this dynamic. Without deliberate effort, it can speed up delivery while quietly weakening an organisation’s ability to create and sustain expertise. When organisations optimise purely for short-term efficiency, learning is often the first thing to erode. When learning slows, capability follows.
The organisations that will thrive in the GenAI era will not be the ones that simply adopt the tools. They will be the ones that treat learning as core to how they operate.
That includes investing in early-career development, creating environments where experience is accumulated rather than bypassed, and recognising that effective software development has always depended on people who can exercise judgement, reason about systems, and learn continuously, not just produce output.
GenAI feels like another turning point for software development. It’s really just the latest moment in a long, repeating pattern of partial revelation and broad avoidance of how creating software needs to be approached.
Early limits of software development
The “software crisis” of the 1960s was the first time this became apparent – there was a sudden leap in computing power, huge optimism, and a belief that software development would simply scale to match it. It didn’t. Projects ran late and over budget, systems failed in production, and codebases became unmaintainable.
Systems had become too complex for the informal development practices at the time. The response was software engineering as a discipline, the industry recognising that writing software was not just typing instructions but coordinating human understanding. The answer was more structure, more process, more formality. The underlying assumption, though, was that software development could be treated like other branches of engineering: plan carefully, specify up front, then execute
When big up front planning began to struggle to keep up
By the 1990s that model was starting to crack. Several things had shifted. Programming languages and tooling had improved. IDEs, compilers and version control reduced friction. Hardware and compute continued to become cheaper and more powerful. But most importantly, the internet removed distribution friction. You no longer had to ship physical media or install systems on site. Software changes could reach users almost instantly. The cost of change dropped sharply.
Agile emerged in that gap. Not because people suddenly liked stand ups and sticky notes, but because fast feedback through working software was proving to be more effective than detailed upfront plans.
The problem was that the underlying assumption that software was a construction problem never really went away. Most organisations copied the rituals and missed the point. Agile in practice largely became process rather than philosophy.
Software development in the GenAI era
And now GenAI-assisted coding. GenAI has emerged from the continued trend of compute becoming more powerful and cheaper, combined with the sheer volume of data now available as a result of the internet era. The underlying concepts of machine learning have existed for decades, but only recently have the economics and data volumes made it practical.
As a result, the distance from intent to working artefact has shrunk again. You can explore ideas, generate alternatives, test assumptions and see consequences in hours rather than days.
And yet, software engineering is still, to this day, largely treated as a construction problem. Most teams operate as feature factories, fed tickets from a backlog, optimising for “velocity” rather than fast feedback and being able to quickly adapt and respond to new information. Work is broken into tasks, handed off between roles, and judged by output rather than learning.
What building software is really about
At its core, software exists to solve one problem: managing the flow of information. Information is not static. It is provisional, contextual, and constantly changing. Every use of a system creates new information that should influence what happens next. Many of its most important inputs only appear once it is in use.
Software is therefore less a construction problem and more an ongoing conversation between users, systems and decisions. Its quality lies in the strength of its feedback loops and how effectively it enables learning and adjustment as conditions change.
Technology advances keep reducing the cost of building software, but organisations keep failing to adapt how they approach it. Each era exposes that mismatch more visibly, without resolving it.
The organisations that will thrive in this era will be the ones that optimise for learning over output, feedback over plans, and understanding over speed.
Coding has never been the governing bottleneck in software delivery. Not recently. Not in the last decade. And not across the entire history of the discipline.
I wrote this post in response to the current wave of people claiming “AI means coding is no longer the bottleneck” and to have somewhere to point them too – a long trail of experienced practitioners highlighting the main constraints in software delivery have always sat elsewhere.
That doesn’t mean coding speed never matters. In small teams, narrow problem spaces, or early exploration, it can be a local constraint, for a time. The point is that once software becomes non-trivial, progress is governed far more by other factors – such as understanding, decision-making, coordination and feedback – than by the rate at which code can be produced.
By the late 2000s, it was a meme
In 2009, Sebastián Hermida created a sticker that shows a row of monkeys hammering on keyboards under the caption “Typing is not the bottleneck”. It spread widely and became a piece of shared shorthand in the software community. He didn’t invent the idea. He turned it into a meme because, by then, it was already widely understood among practitioners.
Kevlin Henney, a long-standing independent consultant and educator, known for decades of international conference keynotes and training on software design, has said he was using the phrase in talks and training as far back as the late 1990s. The same wording also appeared in a 2009 blog post by GeePaw Hill, (a software developer, coach, and writer best known for his work in Extreme Programming), challenging the notion that practices like TDD and pair programming slow teams down.
Whether Hermida encountered the phrase via Henney, Hill, or elsewhere doesn’t matter. By the late 2000s, this way of thinking was already widely shared and known among many experienced practitioners.
Around 2000, the constraint was already understood to sit upstream
In 2000, Joel Spolsky, then a well known, prolific, blogger and co-founder of Fog Creek Software (then later Stack Overflow and Trello), published a series of articles on Painless Functional Specifications.
The articles are often remembered as an argument for writing specs, and they are. The more important point is why Spolsky cared about them. He argued that teams lose time by committing to decisions too early in code, then discovering problems only after that code exists.
You don’t have to agree with Spolsky’s preferred balance between upfront and iterative design to accept the premise. Twenty-five years ago, he was already pointing out that the limiting factor was deciding what to build and how it should behave, not how quickly code could be produced – “failing to write a spec is the single biggest unnecessary risk you take in a software project.”
Today, with GenAi there’s lots of interest in “specification driven development.” as if it’s the hot new thing. It’s not. It reflects the same underlying constraint Spolsky was describing in 2000. Across the lifecycle, code has long been, relatively speaking, easy to produce. The harder part has always been deciding what should exist, and living with the consequences once it does.
In the early 1990s, mainstream engineering literature said the same thing
In 1993, Steve McConnell published Code Complete, a book that has remained in print for decades and is still widely recommended as a foundational text in professional software development. The book was intended to consolidate what was known, from research and industry practice, about how professional software is actually built.
Drawing on a wide range of studies, McConnell showed that the dominant drivers of cost and schedule are not the act of coding itself, but defects discovered late – during system testing or after release – and the resultant cost of rework. Those defects overwhelmingly originate in requirements and design rather than during coding itself.
Even in the punchcard era, coding was not the bottleneck
Whilst programming was painfully slow by modern standards, it was still fast compared to the time it took to learn whether the code worked. Programs were submitted as batch jobs and queued for execution, with results returning hours or even days later. Any mistake meant correcting the code and starting the entire cycle again.
In 1975, Fred Brooks published The Mythical Man-Month, one of the most cited and enduring books in the history of software engineering, drawing directly on his experience building large IBM mainframe systems in the batch and punchcard era. Brooks’s essays focused on coordination, communication, and conceptual integrity – implying that the dominant challenges lay elsewhere than code production.
In Brook’s now famous essay No Silver Bullet, added to the anniversary edition of The Mythical Man-Month (1986), he made his core argument explicit. Software is hard for reasons that tools cannot remove. He distinguished between essential complexity, the difficulty of understanding a problem and deciding how software should behave, and accidental complexity, which comes from tools, languages, and machines. Decades of tooling improvements reduced accidental complexity to the point where there was, even by 1986, no order of magnitude benefit to be had from further tooling improvements.
At a similar time to the first edition of Brook’s book, in Structured Analysis and System Specification, Tom DeMarco argued for careful analysis and specification precisely because discovering misunderstandings after implementation was so expensive in batch environments.
This was already apparent even earlier. Maurice Wilkes, one of the pioneers of stored program computing, later reflected in Memoirs of a Computer Pioneer his realisation in the late 1940s, that “a good part of the remainder of my life was going to be spent in finding errors in my own programs.” From the very beginning, debugging and verification, not writing code, dominated effort.