Unsurprisingly, there are a lot of strong opinions on AI assisted coding. Some engineers swear by it. Others say it’s dangerous. And of course, as is the way with the internet, nuanced positions get flattened into simplistic camps where everyone’s either on one side or the other.
A lot of the problem is that people aren’t arguing about the same thing. They’re reporting different experiences from different vantage points.
I’ve sketched a chart to illustrate the pattern I’m seeing. It’s not empirical, just observational. It’s more nuanced than this, before camps start arguing about it. This is still an oversimplified generalisation.
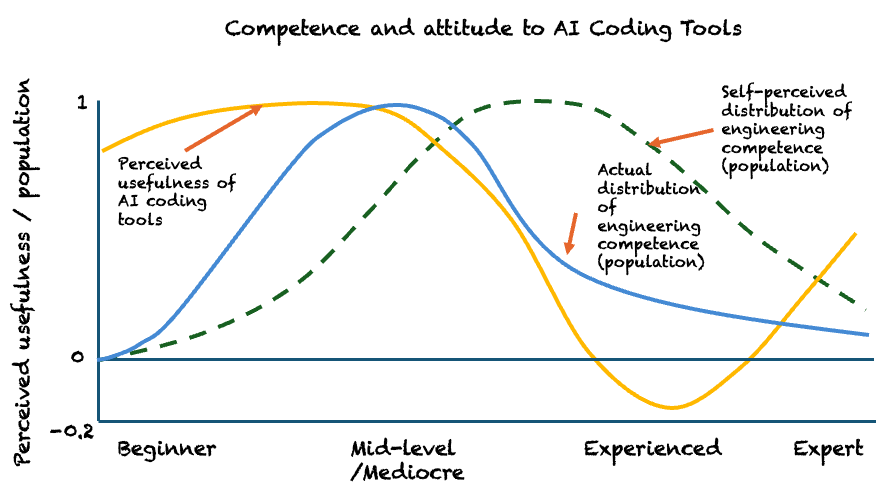
The yellow line shows perceived usefulness of AI coding tools. The blue line shows the distribution of engineering competence. The green dotted line shows what the distribution would look like if we went by how experienced people say they are.
Different vantage points
Look at the first peak on the yellow line. A lot of less experienced and mediocre engineers likely think these tools are brilliant. They’re producing more code, feeling productive. The problem is they don’t see the quality problems they’re creating. Their code probably wasn’t great before AI came along. Most code is crap. Most developers are mediocre, so it’s not surprising this group is enthusiastic about tools that help them produce more (crap) code faster.
Then there’s a genuinely experienced cohort. They’ve lived with the consequences of bad code and learnt what good code looks like. When they look at AI-generated code, they see technical debt being created at scale. Without proper guidance, AI-generated code is pretty terrible. Their scepticism is rational. They understand that typing isn’t the bottleneck, and that speed without quality just creates expensive problems.
Calling these engineers resistant to change is lazy and unfair. They’re not Luddites. They’re experienced enough to recognise what they’re seeing, and what they’re seeing is a problem.
But there’s another group at the far end of the chart. Highly experienced engineers working with modern best practices – comprehensive automated tests, continuous delivery, disciplined small changes. Crucially they’ve also learned how work with AI tools using those practices. They are getting productivity without impacting quality. They’re also highly aware typing is not the bottleneck, so not quite as enthusiastic as our first cohort.
Interestingly, I’ve regularly seen sceptical experienced engineers change their view once they’ve been shown how you can blend modern/XP practices with AI assisted coding.
Why the discourse is broken
When someone from that rare disciplined expert group writes enthusiastically about AI tools, it’s easy to assume their experience is typical. It isn’t. Modern best practices are rare. Most teams don’t deploy to production multiple times per day. Most codebases don’t have comprehensive automated tests. Most engineers don’t work in small validated steps with tight feedback loops.
Meanwhile, the large mediocre majority is also writing enthusiastically about these tools, but they’re amplifying dysfunction. They’re creating problems that others will need to clean up later. That’s most of the industry.
And the experienced sceptics – the people who can actually see the problems clearly – are a small group whose warnings get dismissed as resistance to change.
The problem of knowing who to listen to
When you read enthusiastic takes on AI tools, is that coming from someone with comprehensive tests and tight feedback loops, or from someone who doesn’t know what good code looks like? Both sound confident. Both produce content.
When someone expresses caution, are they seeing real problems or just resistant to change?
The capability perception gap – that green dotted line versus reality – means there are probably far fewer people with the experience and practices to make reliable claims than are actually making them. And when you layer on the volume of hype around AI tools, it becomes nearly impossible to filter for signal.
The loudest voices aren’t necessarily the most credible ones. The most credible voices – experienced engineers with rigorous practices – are drowned out by sheer volume from both the mediocre majority and the oversimplified narratives that AI tools are either revolutionary or catastrophic.
We’re not just having different conversations. We’re having them in conditions where it’s genuinely hard to know whose experience is worth learning from.