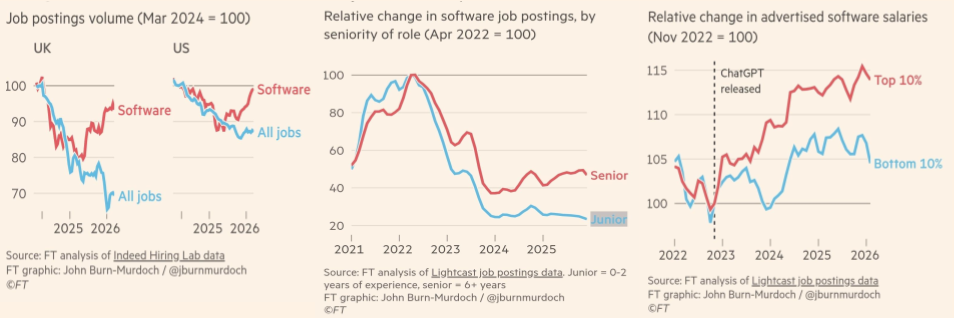
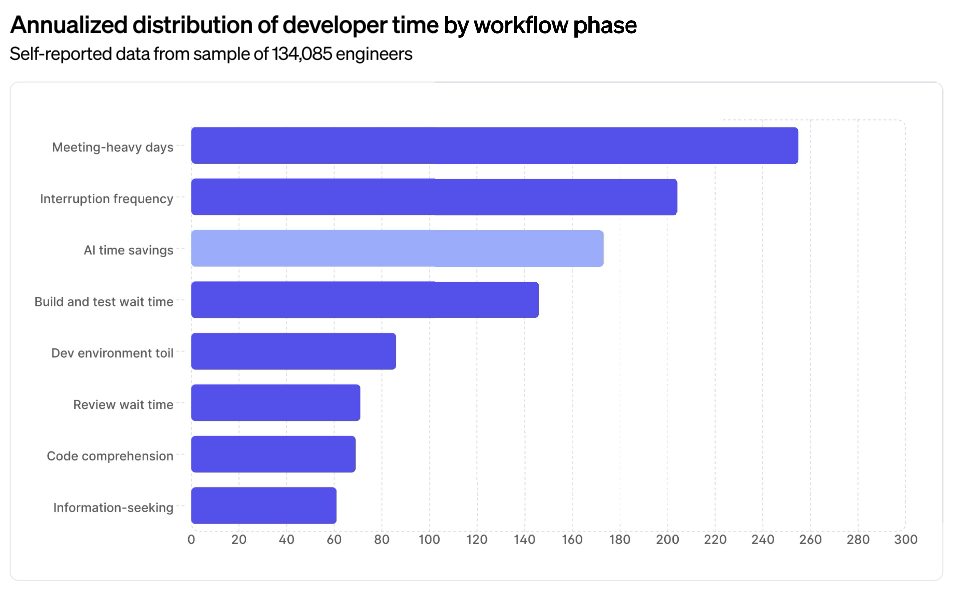
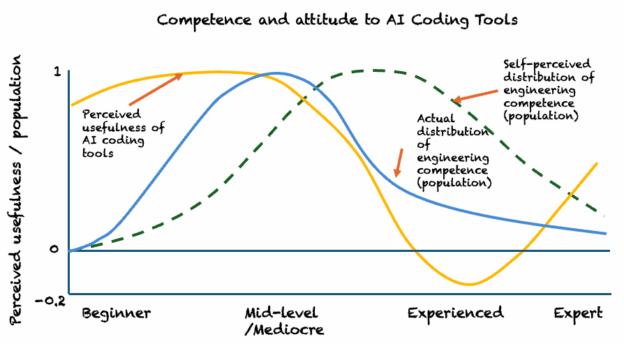
I’ve been trying to work out why successive advances in GenAI models don’t feel particularly different to me, even as others react with genuine excitement.
I use these tools constantly and have done since ChatGPT4 was released nearly 3 years ago. I couldn’t imagine a world without them. In that sense, they already feel as transformative as the web. I’ve been thinking perhaps how its once they become ambient, the magic fades. You get used to them and stop noticing improvements. But the more I’ve thought about it, the more I think there are deeper structural reasons why the experience has plateaued, for me at least.
The lossy interface
All meaningful work starts in a physical, social, constraint-filled environment. We reason with space, time, bodies, artefacts, relationships, incentives, and history. Much of this understanding is tacit. We sense it before we can explain it.
To involve a computer, that reality has to be translated into symbols. Text, files, data models, diagrams, prompts. Every translation step compresses context and/or throws information away. There is loss from brain to keyboard. Loss from keyboard to prompt. And loss again when the output comes back and has to be interpreted.
GenAI only ever sees what makes it across that boundary. It reasons over compressed representations of reality that humans have already filtered, simplified, and distorted.
Better models reduce friction within that interface, but they don’t change its dimensionality. In that respect it doesn’t really matter how “smart” the models get, or how well they do on the latest benchmarks. The boundary stays the same.
Because of that, GenAI works best where the world is already well-represented in digital form. As soon as outcomes depend on things outside its boundary, its usefulness drops sharply.
That is why GenAI helps with slices of work, not whole systems. It is powerful, but fundamentally bounded.
Some real world examples:
- In software development, generating code hasn’t been the main bottleneck since we moved away from punch cards. The far bigger constraints are understanding the problem, communicating with stakeholders, working effectively with other people, designing the system, managing risks and trade-offs, and operating systems in complex social environments over time.
- In healthcare, GenAI can assist with diagnosis or documentation, but outcomes are dominated by staff, facilities, funding, and coordination across complex human systems. Better reasoning does not create more nurses or hospital beds.
In both cases, GenAI accelerates parts of the work without shifting the underlying constraint.
Faster horses, not trains
In that respect, GenAI feels like faster horses rather than trains. It makes us more effective at things we were already doing, writing, code, analysis, planning, and sense-making, but operates on only parts, thin slices of systems.
Trains didn’t just make transport faster. They removed a hard upper bound on the movement of people and goods. Once that constraint moved, everything else reorganised around it. Supply chains, labour markets, cities, timekeeping, and even how people understood distance and work all changed. Railways were not just a tool inside the system, they became the system.
GenAI doesn’t yet do that. It works through a narrow, virtual interface and plugs into existing workflows. But as often as not the real systematic constraints lie elsewhere.
What actually changed the world
A recent conversation reminded me of Vaclav Smil’s How the World Really Works, which I read last year.
Smil highlights that modern civilisation rests on a small number of physical pillars: energy, food production (especially nitrogen), materials like steel and cement, and transport. Changes in these pillars are what led to the biggest transformations in human life. Information technology barely registers at that level in his analysis. He doesn’t deny its importance, but treats it as secondary, an optimiser of systems whose limits are set elsewhere.
Through that lens, GenAI doesn’t (yet) register as a civilisation-shaping force. It doesn’t produce energy, grow food, create new materials, or move mass. It operates almost entirely above those pillars, improving coordination, design, and decision-making around systems whose hard limits are set elsewhere.
That doesn’t make it trivial. But it explains why, so far, it looks closer to previous waves of information technology than to steam or electricity. It optimises within existing constraints rather than breaking them.
The big if
Smil’s framing doesn’t say GenAI cannot matter at an industrial scale. It says where it would have to show up. GenAI becomes civilisation-shaping only if it materially accelerates breakthroughs in those physical pillars – things that change what the world can physically sustain.
This is where “superintelligence” comes in. If GenAI can explore hypothesis spaces humans cannot, design and run experiments, or compress decades of scientific iteration into years, resulting in major scientific breakthroughs, it moves from optimising within constraints to changing them.
This is also where my own doubts sit. Many think just scaling what we have now will get us there. For those that don’t believe that, but are still optimistic about AI’s potential, they turn to world models, embodiment, or agents that can act in the real world. There are sketches and hopes for how this may happen, but as yet, not much more than that.
So while superintelligence is the path by which AI could plausibly become industrial-scale transformative, it’s a long and uncertain one.
What kind of change are we talking about?
If you mean web-scale change, then GenAI is already there. But if we mean the kind of change associated with the industrial revolution (as it’s often compared to) – longer lives, better health, radically different working conditions, step changes in material living standards, then what we have today does not qualify. Historically, those shifts followed from breaking physical constraints, not from better information or reasoning alone.
For me, and why I’m not really feeling successive model improvements, it isn’t that GenAI lacks value. It’s that those improvements don’t change the shape of what’s possible. They operate within the same narrow, lossy interface, so they barely register in practical terms. GenAI still adds value, and already feels web-scale transformative. But until that boundary moves, or something else breaks the underlying constraints, they don’t feel like steps toward an industrial-revolution-scale shift.